앤드류 응 선생님의 딥러닝 전문가 코세라 강의. 2017년에 나온 강의기에 최신 트렌드를 담았다고 볼 수는 없으나 딥러닝 기초를 다지기에 좋은 강의이다. 이미 머신러닝과 딥러닝의 기초적인 내용은 학부와 대학원 시절 강의들을 통해 충분히 배웠지만, 시간이 지나서인지 기초가 가물가물해지기 시작했다. 🤔처음에는 석사 과정에서 다시 기초를 듣는다는 것이 머뭇거려졌지만, 첫 주차 강의를 듣고 그 생각이 바뀌었다. 강의를 통해 이론을 복습하고 실습을 통해 구현 연습을 하니 도움이 많이 되었다. 다른 사람들도 이 강의를 통해 딥러닝 AI 지식 기초를 다질 수 있을 것이라 확신한다. 구글 부트캠프 2020 코스에서도 본 강의를 들으면 머신러닝 엔지니어 기초 자격을 획득했다고 가정하니 좋은 강의임에 틀림없다.
본 코스는 총 5개로 구성되어 있으며, 배웠던 내용을 개인적인 복습 차원에서 요약 및 정리를 하려고 한다. 역전파 등의 복잡한 수식 과정은 유튜브에서나 다른 자료에서 훨씬 더 잘 설명하고 있으니 생략한다.
Course 1. Neural Networks and Deep Learning
Logistic Regression
딥러닝을 배우기에 앞서 먼저 기초가 되는 Logistic Regression 에 대해 익혀야 한다. Logistic Regression 은 어떤 x (features)를 통해 Y를 예측하는데 활용되는 기본 선형 확률 모델이다. 강의에 나왔던 예시로 예를 들자면 어떤 사진이 주어졌을 때 사진이 고양이인지 강아지인지 판단하는 이진 분류 문제를 풀기 위해 사용되는 기초 모델이다.
고양이인지, 강아지인지에 대한 예측 정확도를 Logistic Regression은 0에서 1 사이의 확률로 표현해준다. 이를 수식으로 나타낸다면 예측값인 $\hat{y}$은 다음과 같이 표현할 수 있다.
$$\hat{y} = \sigma(W^Tx + b)$$
- $\sigma$ : 시그모이드 함수
- W, b : 모델의 파라미터
여기서 중요한 부분은 sigmoid함수인데, 아래 그림을 통해 sigmoid함수는. 어떠한 값을 받아도 0 ~ 1 사이의 값으로 변환해주는 것을 볼 수 있다. 즉, Logistic Regression 은 0 ~ 1 사이의 확률 값으로 어떤 예측에 대한 수치를 표현하는 것이 핵심이다.
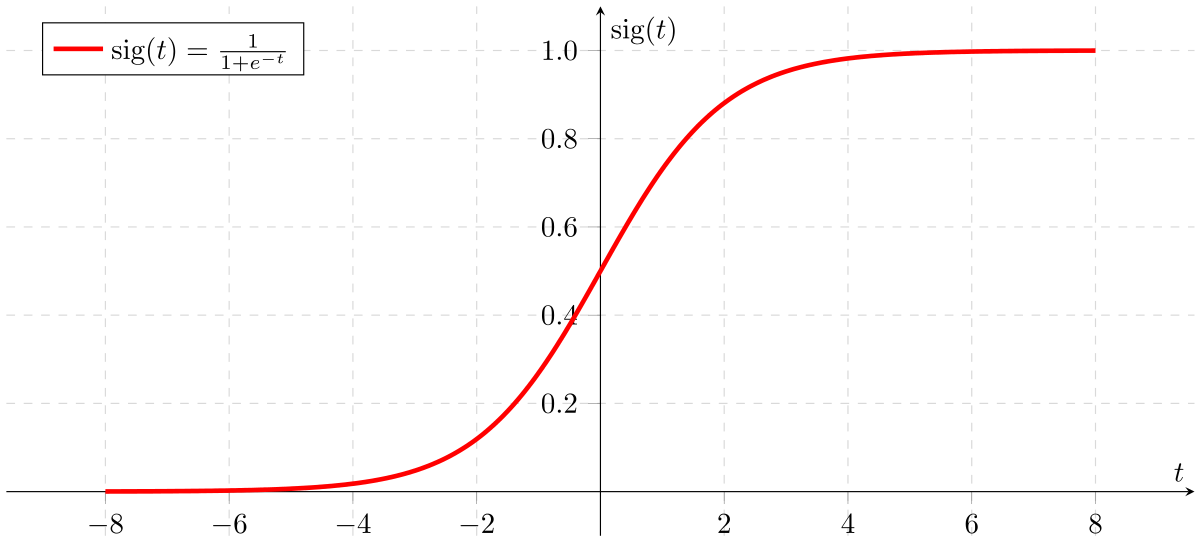
비용 함수
Logistic Regression 모델을 훈련시키기 위해서는 먼저 Loss function를 정의해야 한다. 이전에 Logistic Regression 으로부터 나온 예측값을 $y$가 아닌 $\hat{y}$으로 표현했다. 이 예측값을 원래의 정답과 비교하면서 모델을 개선한다. 만약 모델이 초기에 고양이 사진을 강아지로 예측했다면, 고양이로 예측하도록 모델의 파라미터를 수정해야 한다. 다시 말해 정답과 예측값의 차이를 줄여나가는 것이 학습의 목적이며, 정답과 예측값의 차이를 수식으로 나타낸 것이 비용 함수이다. 비용 함수는 Loss function, Cost function 등으로 표현되며 풀어야 하는 문제에 따라서 식이 다르다.
Logistic Regression에서는 이진 분류를 다루기에 단순히 아래처럼 예측값과 정답 간 차이의 제곱을 Loss function으로 설정할 수도 있다.
$$L(\hat{y}, y) = \frac{1}{2}(\hat{y} - y)^2$$
그러나 gradient descent (모델이 훈련 과정에서 찾아야 할 최소값)의 최적 값을 찾기 힘들다는 단점 때문에 비슷한 역할을 하는 로그 함수를 사용한다.
$$L(\hat{y}, y) = -(ylog\hat{y} + (1-y)log(1-\hat{y}))$$
직관적으로 위 식은 만약 $y$가 1일 경우 비용 함수를 최소화하기 위해 $\hat{y}$가 커지는 방향으로 학습을 진행하고, $y$가 0일 경우 $\hat{y}$이 작아지는 방향으로 학습이 진행되기 때문에 적절한 식이라고 볼 수 있다.
Loss function과 유사한 용어로 Cost function도 존재한다. 개념적으로 차이가 거의 없지만 한 가지 차이가 있다면, Loss function은 단일(single) training example에 대한 error이며, Cost function은 전체 training set에 대한 error의 평균이다. 둘 다 말하고자 하는 것은 궁극적으로 같기에 이후 용어는 비용 함수 $J$ 로 통일하겠다.
Gradient Descent
정리하자면 모델이 어떠한 input x를 보다 더 정답에 가깝게 예측하기 위해서는 비용 함수 J를 최소화해야 한다. 이 비용 함수는 $y$와 $\hat{y}$로 정의되며 파라미터 W와 b로 구성되어 있다. 비용 함수를 정의하고 나서 다음 단계는 비용 함수 J를 최소로 만드는 W와 b를 찾는 것이다. 적절한 파라미터 W와 b를 찾기 위해 사용되는 알고리즘이 gradient descent algorithm (경사 하강법)이다. 경사 하강법은 어떤 함수의 최솟값을 찾기 위해 사용되는 일반적인 방법으로, 함수의 기울기를 구하여 가장 기울기 경사가 급격한 방향으로 이동하는 과정을 일컫는다. 아마 이 분야를 처음 접하면 일차 난관이 여기일 것이라 생각된다. 말은 어렵지만 사실 어렵지 않은 개념이다.
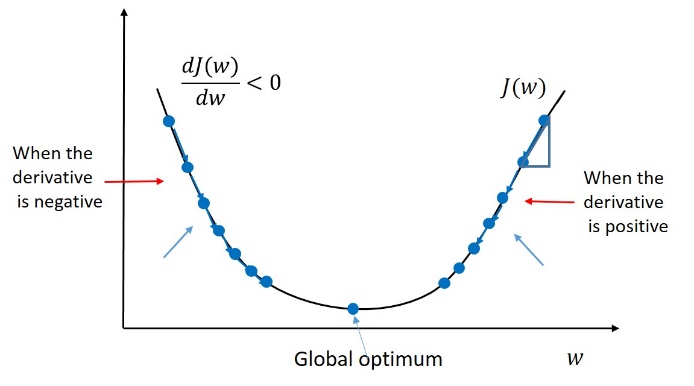
(b는 고려하지 않고 w만 고려함)
<목적: 비용 함수 J를 최소화하는 어떤 파라미터 w와 b를 찾는 것>
위 그림은 비용 함수 J를 간략히 표현한 이차원 그래프이다. 모델은 비용 함수를 최소로 만드는 값인 global optimum 에 도달하기 위해 함수의 기울기에 따라 w를 업데이트해나간다. 만약 기울기가 음수라면, global optimum이 (가장 기울기 경사가 급격한) 오른쪽에 있을 것이라고 가정한다. 그러므로 [w = w + 양수]로 업데이트. 만약 기울기가 양수라면, global optimum이 (기울기 경사가 급격한) 방향인 왼쪽에 있을 것이라고 가정하고 [w = w - 양수]로 업데이트. w 업데이트 과정을 식으로 표현한다면 다음과 같다.
$$w := w - \alpha \frac{dJ(w)}{dw}$$
- $\alpha$ : 학습률. w가 다음에 얼마나 이동할 지에 대한 수치 값
- $\frac{dJ(w)}{dw}$ : w의 변화율 (기울기)
모델은 계속해서 위 식을 반복함으로써 w를 새롭게 갱신해나가며 학습을 진행한다. 여기서 나오는 개념이 역전파 개념이다. 그렇다면 더 자세하게, 어떻게 학습이 진행되는가? 는 생략. 유튜브를 찾아보자. 앤드류 응 선생님도 말씀하셨지만 세부 수식을 모두 이해할 필요는 없으니 부담 느끼지 말자. 이해하면 좋지만, 요즘은 프레임워크가 대부분 알아서 해준다.
Neural Network
Logistic Regression에 여러 hidden Layer를 추가하여 확장한 것이 바로 신경망 모델이다. 코세라 실습 강의 자료로 비교하자면 다음과 같다.

위와 같은 형태의 신경망 모델은 input layer, hidden layer, output layer 총 3가지 레이어가 있는 단순한 형태로, 2-layer 신경망 모델이라 불린다. 일반적으로 신경망 모델에서 input layer는 수로 안 셈. 여기서 hidden layer를 더 많이 (깊게) 쌓은 것을 딥러닝 모델이라 부른다.
Activation functions
모든 학습과 역전파 과정은 Logistic Regression 때와 유사하나, 한 층 쌓였다고 파라미터나 기타 수식이 상당히 복잡해져서 이차 난관이 온다. 우선 새로운 개념도 추가되는데, 단순히 sigmoid 함수를 사용했던 Logistic Regression과 달리 신경망 모델에서는 층마다 activation function (활성 함수)를 달리 설정해주곤 한다. 간단히 활성 함수의 종류와 용례를 언급하고 넘어가겠다.
Sigmoid
- 한 가지 예외, 이진 분류 문제의 출력층일 경우를 제외하고는 딥러닝에서 거의 사용되지 않는다.
Tanh

- 거의 대부분
sigmoid보다 성능이 좋다. - 정확한 이유는 알 수 없지만 출력 값이 -1에서 1 사이의 값으로 나오면서 평균값이 0에 가깝게 해 주기 때문이라 추정. 일반적으로 평균값이 0이면 데이터가 중심에 오기 때문에 예측 성능이 향상된다고 한다
한편, sigmoid와 tanh의 치명적인 한계는, z 값이 매우 크거나 작을 때 gradient descent가 0에 가깝게 된다는 점이다. 이는 gradient descent의 수렴 속도를 매우 느리게 하기 때문에 역시 딥러닝에서는 잘 사용되지 않는다.
ReLU (Rectified Linear Unit)
앤드류 응 선생님 추천 (웬만해선 ReLU 쓰자!)
- 음수 일 때 0이 되는 것은 단점일 수 있으나, 실제로는 작동 잘한다.
- 빠르다! (함수가 단순해서)
- 0으로 가면 학습 속도 저하의 가능성이 있지만, 일반적으로 z는 양수이기 때문에 빠른 편.
이후 ReLU의 변형태인Leaky ReLU가 등장하였지만, 딱히 좋은 성능 차이를 내진 않는다고 한다. 거의 대부분 작동이 잘 된다고 한다. 2017년 강의라서 많이 달라졌을 수도 있지만, 본인도 최근 프로젝트에서 ReLU를 주로 사용했다. (tmi: 앤드류 응 선생님이 굳이 Leaky? 라고 하셨음)
딥러닝 모델은 왜 효과적인가?
그밖에 강의에서 나온 구체적인 수식은 생략하고, 왜 딥러닝 모델이 효과적인 가에 대해서 한번 정리하고 마무리하겠다.
- Deep Neural Network는 feature들을 representation 한 뒤 취합한 것. 그러므로 더 많은 layer가 있을수록 더 많은 representation이 가능하다. 일반적으로 초기 층에서는 음소, 모서리 등의 비교적 간단한 low level 정보를 배우고 중기와 후기 층으로 갈수록 점점 정보를 취합하여 복잡한 정보를 배울 수 있게 된다. (e.g., 모서리.. 코.. 얼굴, 음소.. 단어.. 문장)
- Exponentially computational large when shallow
layer 수가 적으면 y를 잘 예측하기 위해 많은 노드가 필요한데, 이건 오히려 layer가 적을 때보다 계산량이 많다.
Course 1에서는 딥러닝을 배우기 이전에 기초가 되는 Logistic Regression을 다루었고, 여러 기본 용어와 개념을 배웠다. Course 2에서는 보다 정교하게 모델을 구현하기 위한 여러 실용적인 테크닉을 배운다. 이후 파트 역시 추후 정리 예정!